197,717 Lines of Code Later...
After taking 18 computer science classes at Harvard (17 in CS, 1 in EE), I was curious to see exactly how many lines of code I have written for assignments these past four years. I was also curious what the breakdown would be for the different programming languages I’ve learned over the years.
After looking through the archives of my computer, I calculated that I wrote 197,717 lines of code (141,008 insertions, 56,709 deletions) for my classes in the past four years! In fact, I believe this is actually an underestimate. In this post, I’ll talk about how I calculated this number, and assumptions I made when calculating this number.
Examining my git log
Fortunately, except for freshman year, I used git for all my projects and assignments. As a result, I can compute the number of lines of code I wrote by examining by git log history. Using git made calculating my contributions on group projects especially easy as git keeps track of who authored each commit. Furthermore, by examining the insertions and deletions of each commit, as opposed to examining the line count at the HEAD of the branch, I can see a more accurate number of lines I wrote and deleted, as opposed to the final count at the end of the assignment/project.
For each git repository, I did the following:
-
Determine which commits were authored by me, using the following command:
git log --author=Kenny --oneline. -
For each of those commits, examine the insertion/deletion count for that commit, broken down for each file:
git show COMMIT --oneline --numstat -
Aggregate those stats by file name across all the commits in a repository, then aggregate those stats by file type.
-
Do this across all the git repositories for all the courses I took.
If you want to examine your own stats across a repository, you can check out my python counting script. Here’s a snippet of the relevent code performing the steps above.
import subprocess
def command(s):
"""
Runs the shell command and returns the stdout as a list
of strings.
"""
proc = subprocess.Popen(s,
stdout=subprocess.PIPE,
stderr=open(os.devnull, "w"),
shell=True)
# strip trailing newline characters
lines = proc.stdout.readlines()
return [l.strip() for l in lines]
def commits_by_author(author):
"""
Returns the list of commit hashes by the given author
"""
lines = command("git log --author=\"%s\" --oneline" % author)
return [l.split(" ")[0] for l in lines]
def commit_stats(commit):
"""
Returns a mapping of filename -> (additions, deletions)
"""
lines = command("git show %s --oneline --numstat" % commit)
assert(len(lines) > 0)
# the first line is just a repeat of the hash, so skip it
lines = lines[1:]
# stats are of the form:
# additions deletions filename
stats = {}
for l in lines:
l = l.strip()
if l == "":
continue
addition, deletion, fname = l.split()
if addition == "-":
addition = "0"
if deletion == "-":
deletion = "0"
addition = int(addition)
deletion = int(deletion)
stats[fname] = (addition, deletion)
return statsNotes
I followed these rules when calculating my total line count.
-
Ignore autogenerated, binary, or raw data files when calculating a line count. When I performed the count on my various git repositories, I noticed that I was not always very disciplined on what I was checking into the repository. Often, courses would want us to submit files that were autogenerated, and so I checked in autogenerated files, binaries, images, csvs, etc. into the repository. Thus, I made an option in my scipt to ignore certain file extensions so that I do not get an inflated line count. Furthermore, I took the notion of “code” to mean anything that was not autogenerated, so I included file types like
.tex,.txt,.mdandREADMEas code (as long as they were not autogenerated). -
Prefer underestimates over overestimates. I did not know how to use git freshman year, and as a result, I cannot get an accurate count for the number of lines of code for CS50, CS51, or CS179. As a result, I only included code that I entirely wrote myself, which excludes modifying code from distribution code from a problem set, and code I wrote as part of team projects. For CS51, I had the original tarball distribution for some of the assignments, so I was able to diff the distribution code with my final assignment submittion. As a result of this exlcusion, the line count for these three courses is much smaller than it actually is.
-
Only include code written for assignments. As a result, I did not count lines of code written for section or lines of code I wrote when TFing these past 3 years.
Classes I’ve Taken
For reference, here’s the list of the computer science classes I’ve taken and when I took them (and possible links to related blog posts).
- CS50 - Introduction to Computer Science (Fall 2010)
- CS51 - Abstraction and Design (Spring 2011)
- CS179 - Design of Usable Interactive Systems (Spring 2011)
- CS61 - Systems Programming and Machine Organization (Fall 2011)
- CS153 - Compilers (Fall 2011)
- CS124 - Algorithms and Data Structures (Spring 2012)
- CS262 - Introduction to Distributed Computing (Spring 2012)
- CS207 - Systems Development for Computational Science (Spring 2012)
- CS121 - Introduction to Theory of Computer Science (Fall 2012)
- CS283 - Computer Vision (Fall 2012)
- CS181 - Artificial Intelligence (Spring 2013)
- CS161 - Operating Systems (Spring 2013)
- CS261 - Research Topics in Operating Systems (Fall 2013)
- CS109 - Data Science (Fall 2013)
- CS91r - Supervised Reading and Research with Jim Waldo (Fall 2013)
- CS165 - Data Systems (Spring 2014)
- CS91r - Supervised Reading and Research with Margo Seltzer (Spring 2014)
- ES50 - Introduction to Electrical Engineering (Spring 2014)
Results
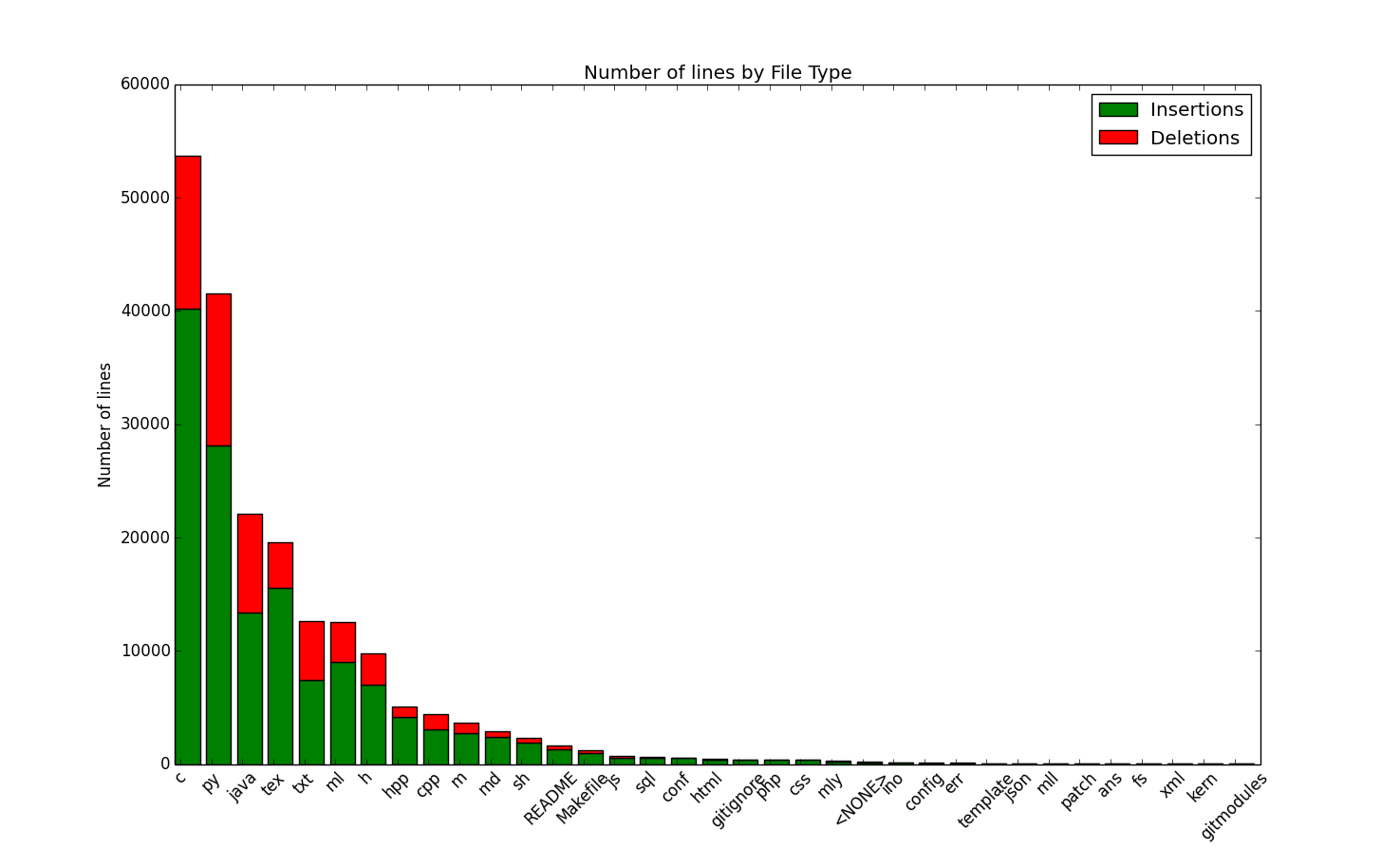
It’s not a surprise for me that I have written more C code than any other language in college,
but it surprised me that python was a close second. However, I realized that I
now use python as my goto language for prototyping and data analysis, and I’ve used
python in more classes than any other class (CS283, CS181, CS109, both CS91r’s, ES50, CS261)
compared to C (CS61, CS161, CS165). I was surprised the java count was so high,
as I have used java mainly in internships. I realized that this came from
CS124 (I used java for Mitzenmacher’s programming assignments) and for CS262
(you gotta use java if you’re in Jim Waldo’s class!). Furthermore, I was shocked
that the ocaml (.ml) line count was so low, as I felt like I wrote much more code
when taking CS153 (Compilers). However, I haven’t written ocaml code for a class since
compilers, and so this count makes sense.
I was a bit surprised at first on why the theoretical classes (CS124, CS121) had
such a high line count, and then I realized it was mostly due to .tex files.
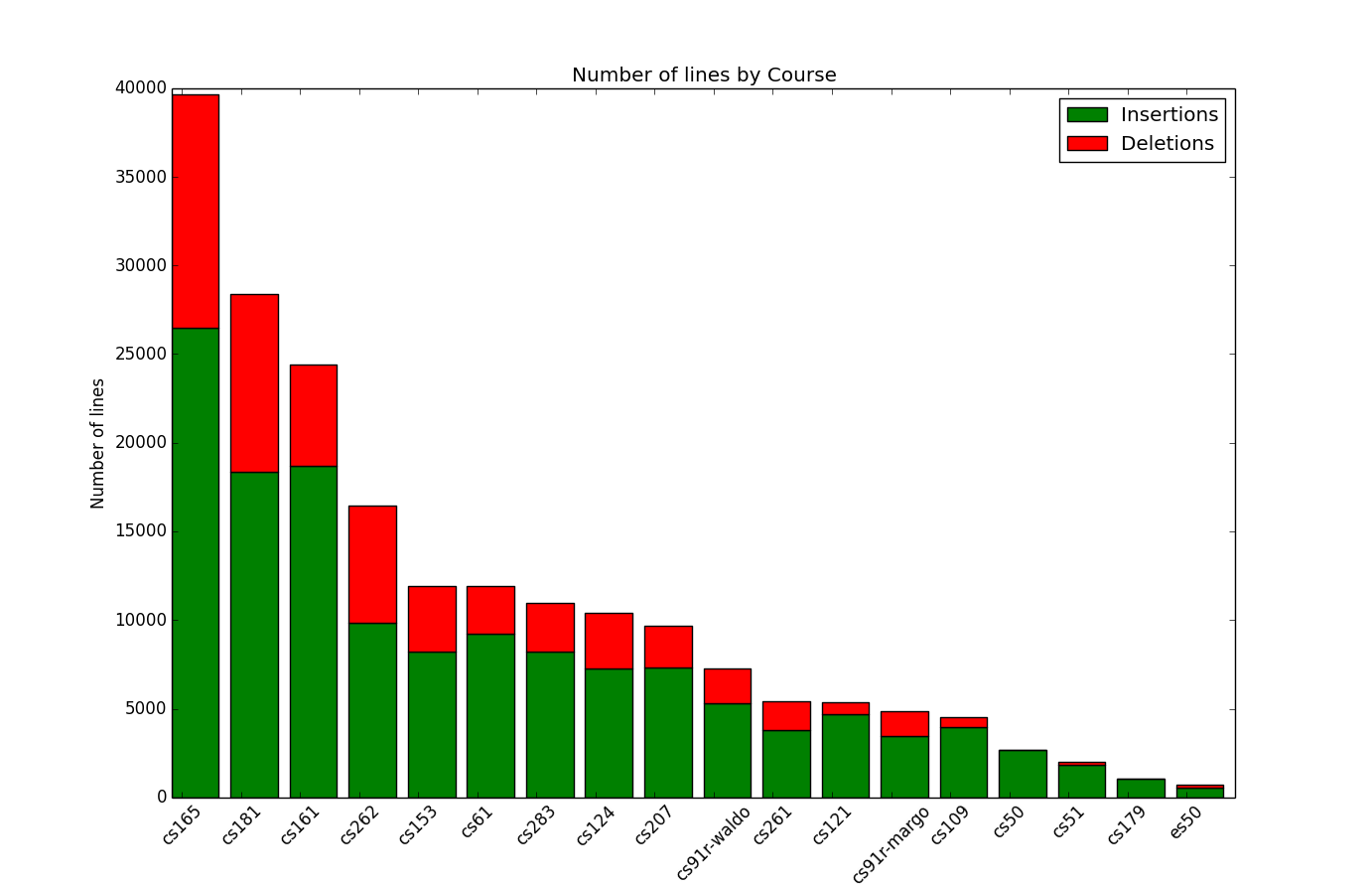
CS161 is often considered the most difficult and time-consuming class at Harvard, and so I thought that CS161 would probably have the highest line count. I was surprised that CS181 and CS165 beat the CS161 count. I believe that because there was no distribution code for CS165 (Data Systems), I had to write a lot more (but less interesting) code to make all the glue for my database. For CS181, the course and assignments were so disorganized the year I took it, and as a result, there were frequent large commits that were mostly overhaul and rewriting everything.
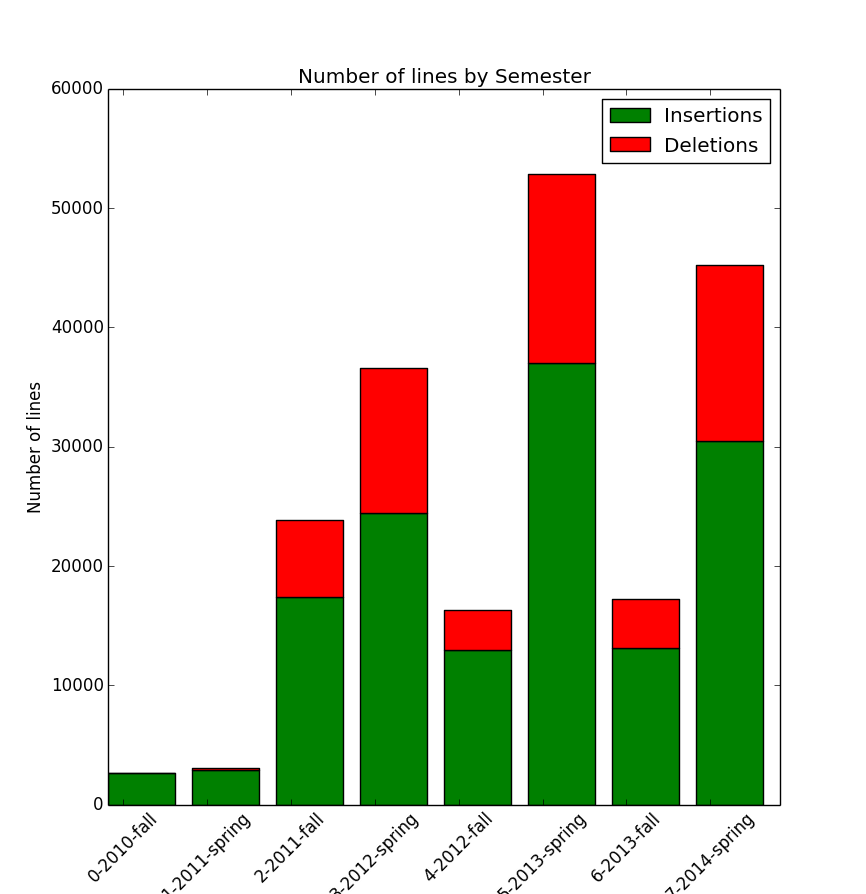
When examining the line count by semester, my spring semesters have a much higher line count than my fall semester, and my Spring 2013 semester has the highest count (not a surprise! I was taking CS161 and CS181 at that time).
Conclusion
In the end, I calculated that I made 197,717 changes (141,008 insertions, 56,709 deletions) over the past four years. This number is probably an underestimate, but I assume it’s around the ballpark of the true number of lines of code I’ve written in college. This makes me appreciate just how much one can learn and do in four years!